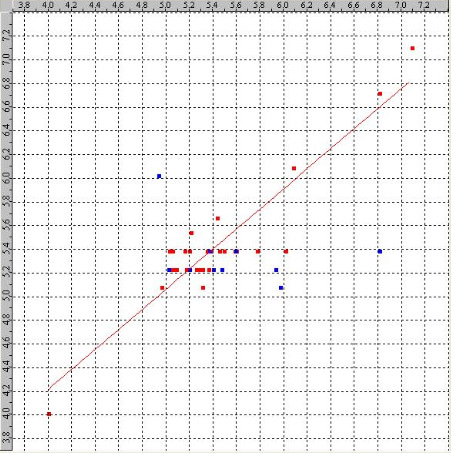
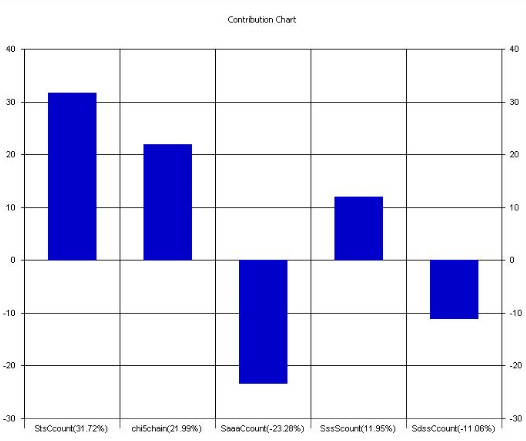
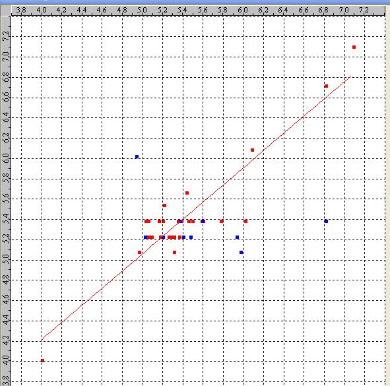
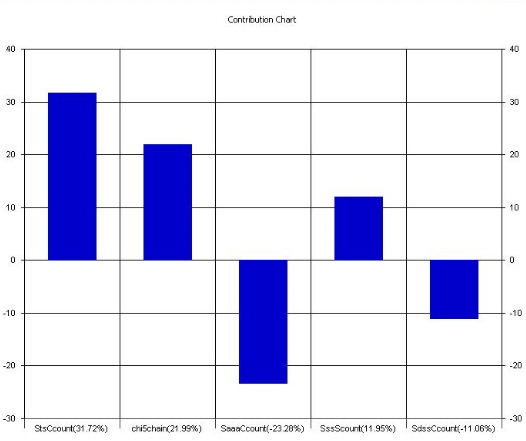


Fact120
Necrotic Enteritis: Managing without Antibiotics Dr. Linnea J. Newman Schering-Plough Animal Health (presented at the PIC's Poultry Health Conference on November 14, 2000) The medical community has expressed concern that antibiotic use in food animals may promote the development ofantibiotic-resistant strains of bacteria that could threaten the human population. While the true relationship betweenantibiotic use in animals and antibiotic-resistant bacteria in humans has yet to be determined, there has been a strong outcryfrom consumers to eliminate antibiotic use from food animal production.